Building Simple Vector Search Engine
10 Feb 2025Building Simple Search Engine: Understanding TF-IDF
I recently built a search engine using Python. Not because I wanted to make something amazing, but because I wanted to understand how search works. Let me explain what I learned.
Basic Idea of Search Engine
When you type something in search box, computer needs to find relevant documents. But how does computer know which documents are relevant? This is where TF-IDF comes in.
TF-IDF looks complicated at first. Even the name is long: Term Frequency-Inverse Document Frequency. But it’s actually simple math that helps find important words in documents.
How My Code Works
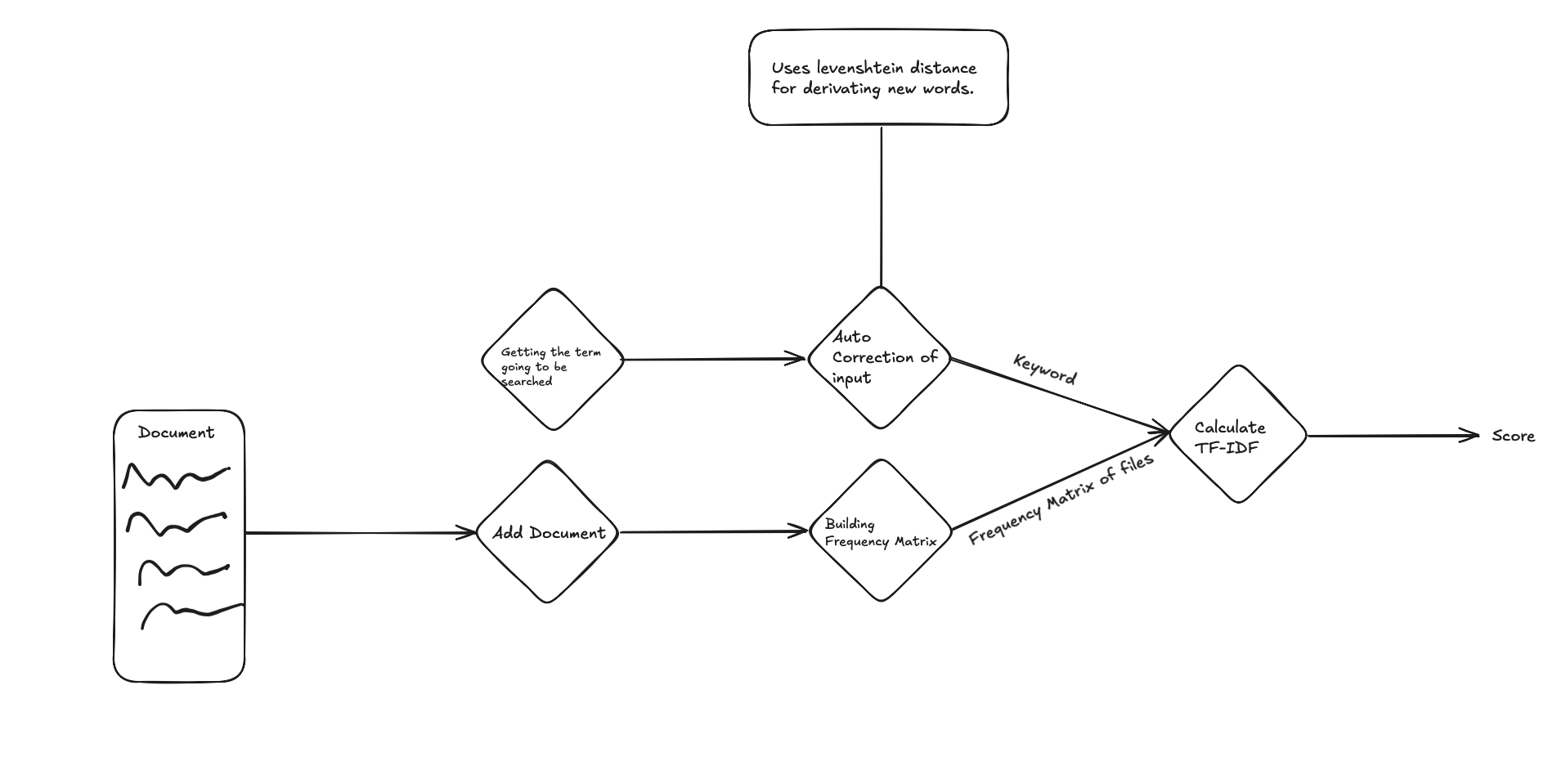
My search engine does these steps:
First, it takes documents and cleans them. Makes everything lowercase, removes dots and commas. This is preprocessing.
After this, it performs autocorrection using Levenshtein distance if the input is not in the vocabulary, i.e., if no matching word is found. This process generates new words and tries to guess what might have been typed.
Here is the example;

When the user typed healt, the system initially guessed it might be help. However, due to the small Levenshtein distance threshold in my implementation, it did not generate health.
Then it looks at words. For every word, it:
- Counts how many times word appears in document
- Checks how many documents have this word
- Uses these numbers in TF-IDF formula
Something interesting: program also fixes spelling mistakes. If you write “serch” instead of “search”, it still works. This happens because of Levenshtein distance - it’s just fancy name for counting how different two words are.
Results Are Not Perfect
TF-IDF is smart, but not perfect. It uses two things to decide if word is important:
- How many times word appears in document (TF)
- How rare word is across all documents (IDF)
For example, if word “apple” appears many times in one document (high TF), but also appears in many other documents (low IDF), program won’t think it’s very important. This helps ignore common words.
But TF-IDF still has limits. It doesn’t understand:
- Word meaning (like “good” and “great” mean similar things)
- Word order (like “dog bites man” vs “man bites dog”)
- Context (like “apple” could mean fruit or computer company)

Technical Details
I used Python with NumPy library. NumPy helps with math operations. Here’s simple example of how it looks:
def tf(self, document_freq_matrix, t):
vector = np.zeros((1, document_freq_matrix.shape[0]))
for idx, freq_matrix in enumerate(document_freq_matrix):
if self.vocab.get(t, None) != None:
vector[0][idx] = freq_matrix[self.vocab[t]] / np.sum(freq_matrix)
return vector
This code calculates term frequency. It’s one part of TF-IDF formula.
Understanding the Calculation Process
Let me explain how our search engine calculates scores. It’s like a recipe - we follow steps to find the best matching documents for your search.
The Steps We Follow
1. Clean the Text (Preprocessing)
First, we make text easy to work with:
- Make all letters small (lowercase)
- Remove special marks like . , ! ?
- Remove extra spaces
Example: “Hello, World!” → “hello world”
2. Make Word List (Vocabulary)
- We collect all unique words
- Each word gets a number (index)
- We use this list for all documents
3. Count Words (Frequency Matrix)
We count how many times each word appears:
- Make a table (matrix)
- Rows are documents
- Columns are words
- Numbers show how many times word appears
Example:
Word: | search | engine | python |
Document1 | 2 | 3 | 1 |
Document2 | 1 | 0 | 4 |
4. Calculate TF (Term Frequency)
For each word:
- Count how many times it appears in document
- Divide by total words in document
- This shows how important word is in that document
Formula: TF = (word count) / (total words)
5. Calculate IDF (Inverse Document Frequency)
For each word:
- Count documents that have this word
- Use special math (logarithm) to give rare words more value
- This helps find special words that aren’t in every document
Formula: IDF = log(total documents / documents with word)
6. Final Score (TF-IDF)
- Multiply TF and IDF
- Higher score means word is more important
- Use scores to find best matching documents
How It All Connects
Think of it like this:
- Clean text → make it simple
- Make word list → organize words
- Count words → see what’s important
- Calculate scores → find best matches
Results with no typo:

Results with typo:

What Could Be Better
Code works but has problems:
- It’s slow with many documents
- Memory usage is not good
- Some edge cases don’t work well
But that’s okay. Main goal was understanding how search engines work, not making perfect system.