Deep Dive into LLMs like ChatGPT
05 Feb 2025This is the summary of first 2 sections of the video from Andrej Karpathy “Deep Dive into LLMs like ChatGPT”. This is a 3 hours video that covers
- Pretraining
- Supervised finetuning
- Reinforcement Learning
This post mostly about my notes during the video session. This video is more to general audience but for closing gaps for some topics it still be watchable. It has nice flow and tone.
I didn’t cover the reinforcement learning section. I found that part very intuitive, he is explaining very very good that I can’t explain with writing and my B1 english 😅. But the key points of the rest are still here.
Pretraining
They are using FineWeb like dataset for data getting. They have own “FineWeb”. Common Crawl is of them.

Representation of text (Tokenization)
Basically we want our model internalises the flow of text. Why we are train for them. We have bunch of characters in the representation right? Internally we can represent them as ‘0’s or ‘1’s right. Here is the how it’s look like.
 as you see we have very long ‘0’s and ‘1’s. But we don’t want long sequence that only made from 2 different symbols. We’re making a tradeoff between symbol size (called vocabulary) and sequence length basically. We want more symbols but shorter sequences. So at this point we are creating bytes which made from 8 bits and if we create bytes our data is looking like this.
as you see we have very long ‘0’s and ‘1’s. But we don’t want long sequence that only made from 2 different symbols. We’re making a tradeoff between symbol size (called vocabulary) and sequence length basically. We want more symbols but shorter sequences. So at this point we are creating bytes which made from 8 bits and if we create bytes our data is looking like this.

In this representation we have 255 different “symbols” (2^8 - 1, it made from 8 bits). But SOTA(state of the art) models usually makes more than that. So they are looking for common pairs like 116 32.

As you see we have bunch of them. They are pairing them and calling the 256th element (normall we have 255 different elements, so they created one). So 116 32 is a new symbol with id = 256. so this is called TOKENIZATION!
How GPT tokenizes?
A nice tokenizer app, that you can explore the process
Select clk100_base this is the GPT4’s tokenizer.
Neural Network I/O
We are taking a windows of tokens fairly randomly from the data and the data windows length range from 0 to maximum size that we decide on then we are putting that sequence to neural network and neural network produces us a new “token” based on their training.
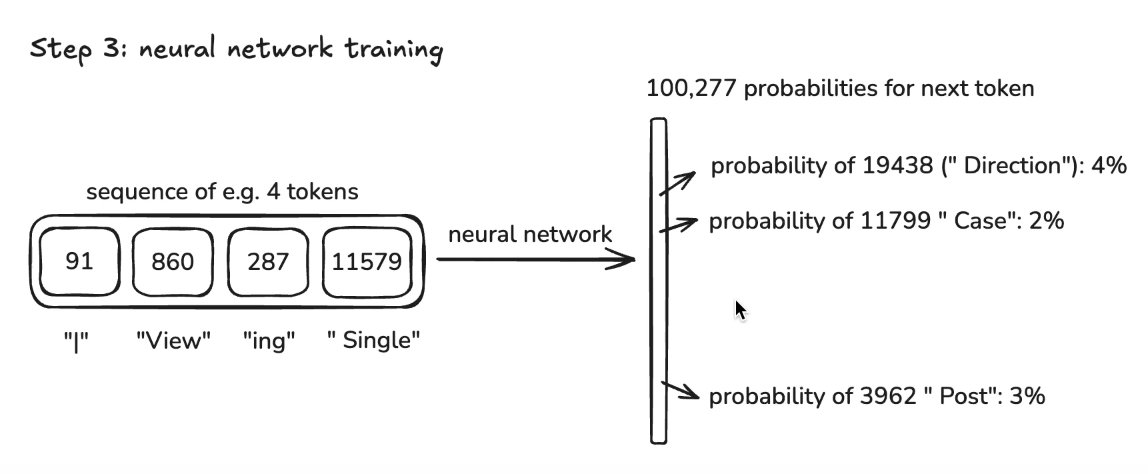
As you see there are different predictions about what might come after 11579 th token. The predictions are the likelihood of next word. The correct answer should be 3962 as Post according to our dataset. During training we want to make our model learn the word Post comes after Single word. And we are doing in batch manner (multiple operations like this at the same time also you can think as parallel). The main aim is to converge to original/datasets patterns in the training data.
Those models can be also MULTIMODAL they can understand voice, images and also they can produce sound, image etc.
Neural Network internals
So let’s think a we have a music set that has bunch of knobs. Basically a neural network is a device that has high amount knobs and in neural networks context we are calling them as parameters or weights. In addition to that we have another block that represents the input sequence tokens or context window.
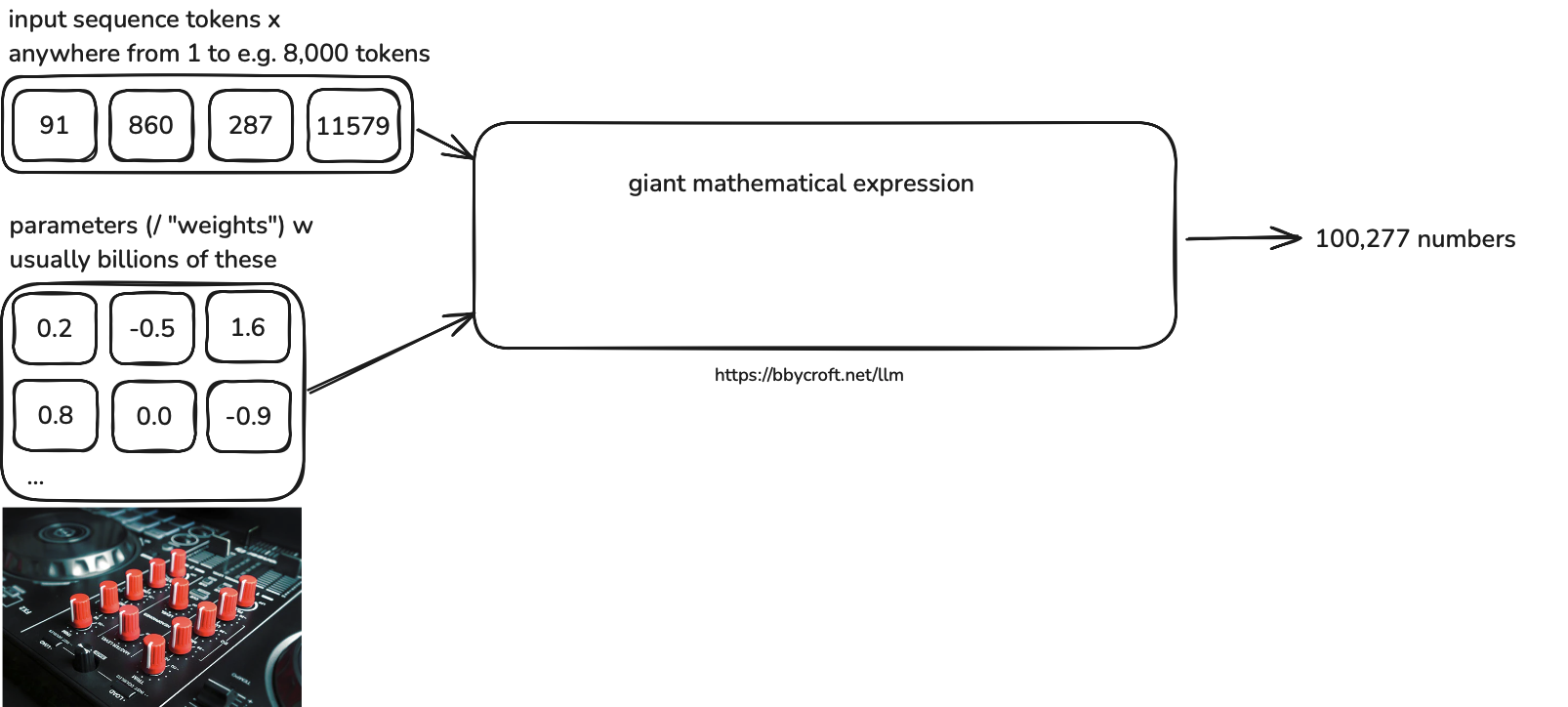
So as you see we are feeding our sequence to a model and that model basically rearranges the weights for increasing the true likelihood of next token. Initially the weights are mostly random and early stages of training they are basically creating nonsense sentences.
Inference
Inference is the word for used execution of the trained machine learning model.
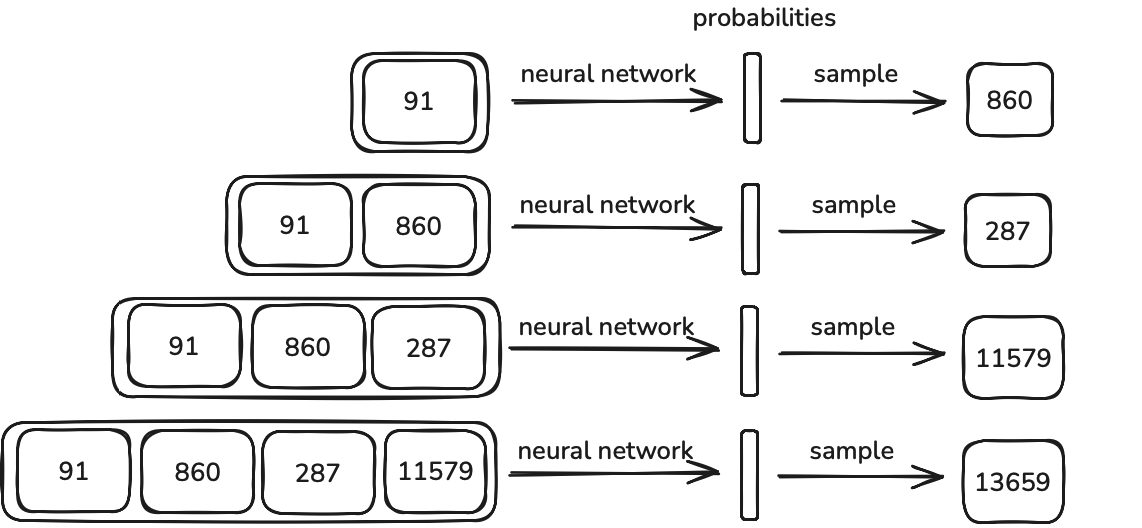
We are giving a initial token to a model and expect to predict next one, after that we are putting predicted to our input sequence and expecting to predict the next one. This procudes goes like that. As we said earlier we are expecting our model to act like our statistical pattern of training data.
Base Model and Instructed model difference
So language models trained on to be guess on our next token. They are like autocompletion but in steroids right. So there are 2 different model
- Proprietary models (ChatGPT, Claude, Gemini)
- Open Models (Qwen, Mistral, GPT-2, DeepSeek-R1, LLama)
The main difference between those models are Open models has optimized weights. So the company that trains those open models have done heavy lifting for us. We are just need to download and use them. But If we try this usually we encounter 2 different model types.
- Base Model
- Instruct Model
The Base Model is the model that what we discussed basically. They are predicting next token but their results far from the AI assistans so at this points we are meeting with the Instruct models. Those models are the Fine-tuned versions of base models (We are going to dicuss what is the fine tuning in a sec). They are fine tuned for answering question or predicting next tokens in generalized format for everyone. For better understanding let’s look the Karpathy’s generations.

This is the LLama-3.1-405B-Base model. Normally we are expecting someting more structured. But as you see it keeps generating. Worth to mention the Max Tokens is set to 512 here. So it stops after generated 512th token.
We need to somehow teach the model that how it can structure their answer more nicely.
The OpenAI team comes with this paper in 2022. This paper the first paper that explains how a model follows user intentions. Long story short they created bunch of structured conversations like

and they trained model with those conversations. At some point they are understanding that how it should be the follow instructions that is given by user.
But you told us the model that only seeing the sequence. How it’s going to see the structured conversation. To overcome this situation we are coming with a new tokens. For example <|im_start|>, <|im_end|>. if we structure them in one dimensional nicely we are having something like this.
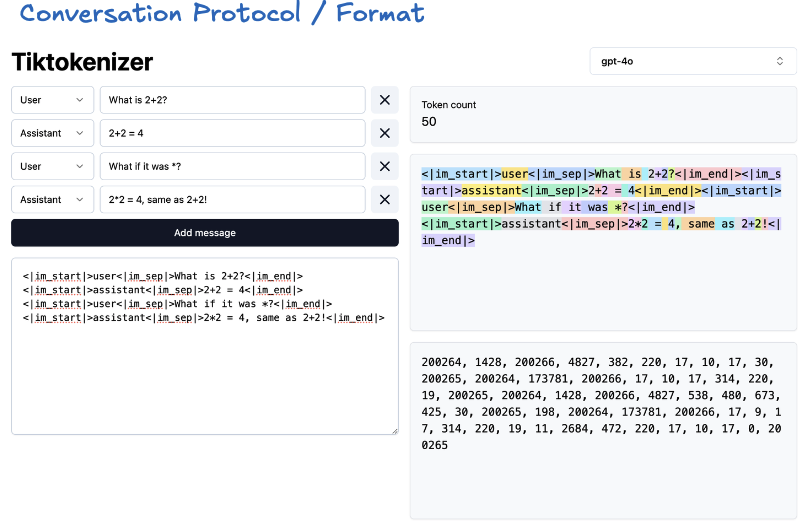
Ok but what about if we ask model something that model doesn’t know?
Hallucinations
At this part Karpathy has very nice examples I very suggest to watch it and he explains well detailed. But for short summary;
Models are just trained for only predicting next tokens. They are not trained for responding like “I don’t know”. If we ask to model tell something about some imaginary person it will come up nonsense and wrong stuff. We are calling this as Hallucination. But newer models know what they know and what they won’t how they know?
Knowledge limitations
The answer is in the LLama3 paper. They are basically discovering edge of the knowledge by asking models some random questions. According to those outputs we can understand are the models are really knowing the stuff that we asked or not(Basically he is asking same questions over and over again and expecting to answer all of them correct). So they curated some questions like those and the just fine-tuned the model like how they did in Instruct the previous part.
We expecting to work because we know if model doesn’t know some neurons are firing up and fine tuning with that actually creates some kind of mapping of this output and those neurons.
He is also mentioning tool usages here for closing the Knowledge gap. For example searching might close the language gap. It also uses specific tokens like <SEARCH_START> or <SEARCH_END> like we mentioned earlier.
Models needs to think
This part is my favorite. He is giving bunch of useful hints that actually opens the mind and create new perspective.
Let’s look the 2 different outputs of this question.
Human: "Emily buys 3 apples and 2 oranges. Each orange costs $2. The total cost of all the fruit is $13. What is the cost of apples?"
The first output:
Assistant: "The answer is $3. This is because 2 oranges at $2 are $4 total. So the 3 apples cost $9, and therefore each apple is 9/3 = $3".
The second output:
Assistant: "The total cost of the oranges is $4. 13 - 4 = 9, the cost of the 3 apples is $9. 9/3 = 3, so each apple costs $3. The answer is $3".
Which one do you think best output and we want generate our model most?
He is mentioning the token time/token compute time at this point. He is thinking the compute is a quantitive thing and should be distributed across the output. For example, in the first output we don’t distributed our compute well. Why? Because answer is in the beginning. The model try to predict answer instantly, token predicted results like memoizing something but totally stochastic. Here we can understand this from this part The answer is $3. On the other hand the second output distributes and slowly process, after some token generations it concludes with the answer.
He also gives best practices about LLM use in general. some of them are here:
- Models can’t count
- Models are not good with spelling.
- Remember they see tokens (text chunks), not individual letters!
- Bunch of other small random stuff
- What is bigger 9.11 or 9.9?
- Models can (and should!) use tools!
- Web search
- Code (/ Python interpreter)
Acknowledgements
Thanks Andrej Karpathy for this video.